LLM帶來的各項AI願景正在進入你我的生活強化學習將使其更有可能完美達成
近期新聞中,最酷的就是台灣傳統媒體民視居然也要推出AI主播,擁抱AI了!而這樣AI應用的場景將會越來越常見!像是5月底時,NVIDIA也發表旗下新AI功能引擎NVIDIA Avatar Cloud Engine(ACE),可以為開發者創建基於LLM控制的遊戲NPC,使玩家在遊玩更身歷其境,如同跟智慧生物對話溝通般探索遊戲的世界。
但要讓LLM可以適應各種不同角色,不同場景,應對不同背景故事,這樣的LLM調教使用傳統的監督式學習絕對跟不上變化的速度的,畢竟不同的背景與情況應對不同的資料處理,這樣文本數據訓練,流暢度以及準確度的調教會花費非常多成本,而這就是我們這邊要介紹的文章的重要處了。
〝IS REINFORCEMENT LEARNING (NOT) FOR NATURAL LANGUAGE PROCESSING: BENCHMARKS, BASELINES,AND BUILDING BLOCKS FOR NATURAL LANGUAGE POLICY OPTIMIZATION〞這篇收錄於ICLR2023的文章討論了如何使用強化學習來優化預訓練的大型語言模型,以便更好地符合人類的偏好。作者提出了一個開源模組化庫RL4LMs,用於使用強化學習來優化語言生成器。其中包含了GRUE基準測試,這是一組由7個語言生成任務組成的測試,它們不是由目標字串監督,而是由捕獲人類「偏好」的自動化度量的獎勵函數監督。除此之外,作者還開發了一種易於使用且高性能的強化學習演算法NLPO(自然語言策略優化),它能有效地減少語言生成中的組合動作空間。此項研究表明,與監督學習的方法相比,強化學習技術通常更能使語言模型符合人類偏好;並且NLPO比以前的策略梯度方法(例如PPO)具有更高的穩定性和性能
研究結論:
-- NLPO更好且更平衡的學習人類喜好以及保留模型流暢輸出的能力
-- 強化學習比監督學習,對於樣本的利用效率更高,一個用了獎勵函數作為強化學習訊號的模型表現比用了5倍多資料的監督訓練還更好!
-- 模型參數使用效率更高,可以用更少的模型參數,但也能達到甚至超過更多參數來監督訓練的模型
所以可以了解到強化學習的活用將可使LLM有更好的表現,且可以用更少的訓練數據達成同樣優秀的語言模型表現,而這樣的發展將會令LLM可以縮小並更適當的活用於各項AI任務中,不論是遊戲亦或是主播…等,願景是非常令人期待的。
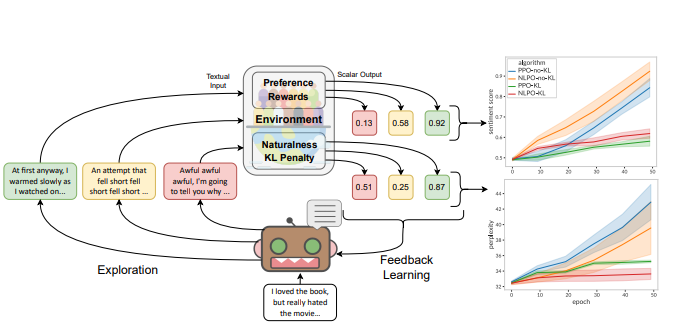 |
| 圖(一) 情感引導(人類的偏好)下的自然語言策略優化(NLPO):本研究,語言模型(即策略)需要根據評論提示產生正面情感的延續作為獎勵的人類偏好的自動代理(這裡:情感分類器)通過與未經明確人類反饋訓練的語言模型的KL散度來衡量“自然性”。 |
 |
| 圖(二) 使用RL4LMs的GRUE基準測試,圖為7個任務的評價指標。Task preference metrics:任務特定的評價指標,Naturalness metrics:選取流暢程度、可讀性等作為評價指標 |
 |
| 圖(三) 判斷何種算法對於人類偏好的對準更好(測試結果是根據圖二中看到的所有相應指標的平均值計算的):supervised + RL > Supervised, PPO,5 and NLPO(監督學習+強化學習比 只用監督或者強化學習的效果要好),Supervised+NLPO >Supervised ≥ Supervised+PPO > NLPO ≥ PPO > Zero-shot |
撰文:徐楷昕
Reference:
1. Ramamurthy, Rajkumar, et al. "Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization." arXiv preprint arXiv:2210.01241 (2022). https://arxiv.org/abs/2210.01241



留言
張貼留言