使用仿生神經的強化學習?
從AlphaGo問世以來,強化學習一直是個熱門的研究題目;利用嘗試錯誤法一步步讓主體(agent,又譯作代理人)學習跟環境的互動,最後得以正確的執行各種任務。 Deep Q Learning 是經典的強化學習實現方式之一;也有許多使用SNN 神經放入 Deep Q Network(DQN)(iThome n.d.) 的嘗試(以下簡稱DSQN)。 但過去的成果都不太好,因爲SNN的Q值若使用firing rate的話,解析度會被限制在模擬長度T的範圍內(1/T, 2/T, …, n/T)。上海交通大學的研究(Chen et al. 2022)以「不會放出激發訊號的神經」爲靈感,開發出了適合SNN的強化學習方法。透過將最後一層的神經激發閾值設為無限大,並將模擬時間內最高的膜電位當作Q-learning中的Q值,來得到浮點數精度的學習效果;同時利用替代函數(surrogate functions)進行反向傳播(Fang et al. 2020)。經過實測,在相同參數下,DSQN可以比DQN在雅達利遊戲(Atari Games)中取得更高的分數。
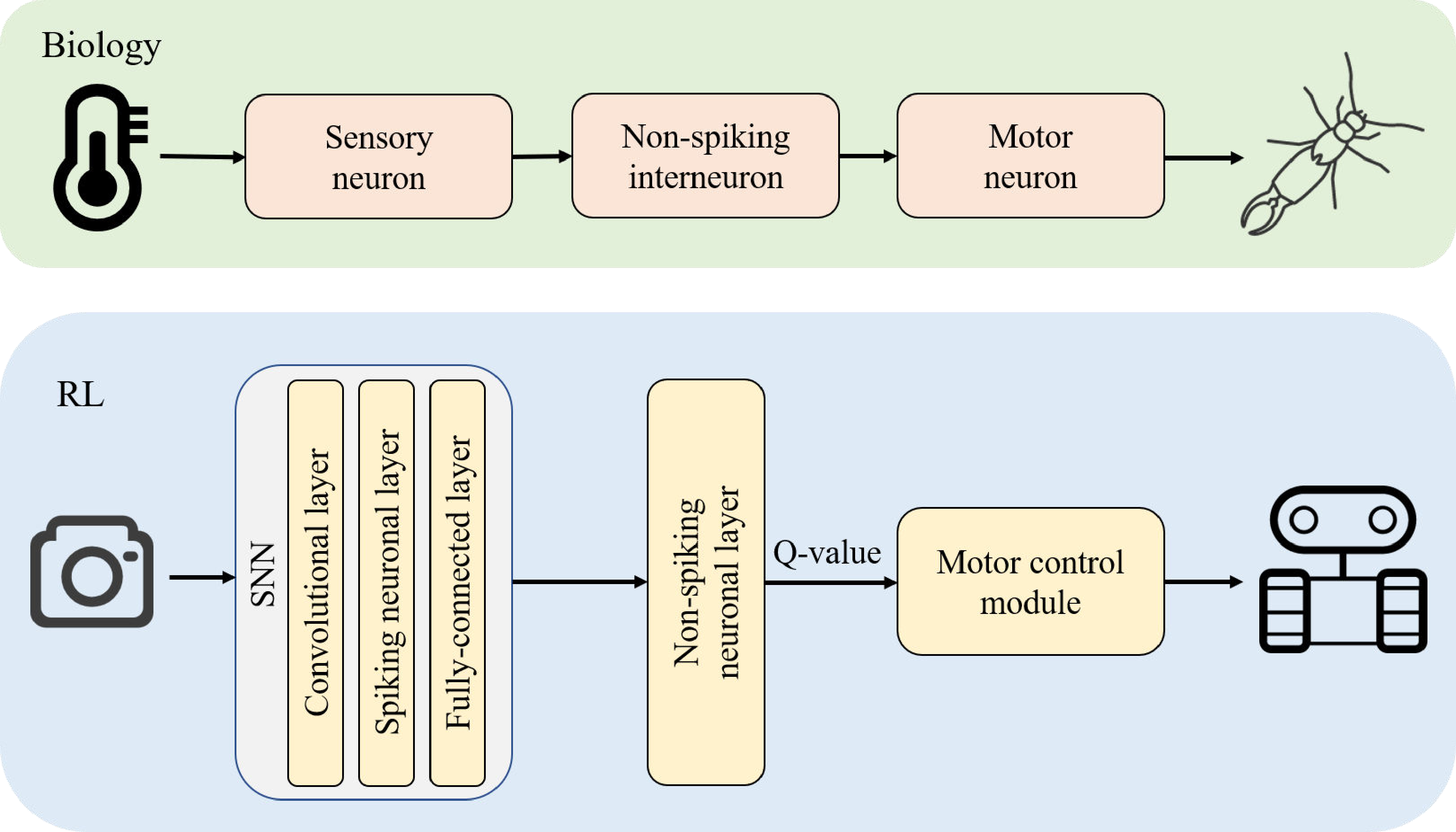 |
| 圖一:從生物的感覺運動系統取得靈感的強化學習方式 |
 |
| 圖二:神經網路架構。使用了捲積-LIF複合層,並在輸出層改為使用不會激發的LI神經。 |
另外,在對抗惡意攻擊方面,作者也針對使用FGSM(Goodfellow, Shlens, and Szegedy 2015)來驗證DSQN對白箱攻擊的強健性,並在各資料集中,得到相比於DQN不一樣程度的進步。
 |
| 圖三:DQN與DSQN的分數比較。 |
SNN乃至於強化學習本身過去有許多挑戰(“Deep Reinforcement Learning Doesn’t Work Yet” n.d.),許多的解方也被研究出來(“Deep Reinforcement Learning Works - Now What?” 2020);期待這樣的算法能幫助我們解決更複雜且快速的問題。
撰文|葉宸甫
參考文章
1. Chen, Ding, Peixi Peng, Tiejun Huang, and Yonghong Tian. 2022. “Deep Reinforcement Learning with Spiking Q-Learning.” arXiv:2201.09754 [Cs], January. http://arxiv.org/abs/2201.09754.
2. “Deep Reinforcement Learning Doesn’t Work Yet.” n.d. Accessed February 20, 2022. http://www.alexirpan.com/2018/02/14/rl-hard.html.
3. “Deep Reinforcement Learning Works - Now What?” 2020. Chen Tessler. https://tesslerc.github.io/posts/drl_works_now_what/.
4. Fang, Wei, Yanqi Chen, Jianhao Ding, Ding Chen, Zhaofei Yu, Huihui Zhou, Yonghong Tian, and other contributors. 2020. “SpikingJelly.” https://github.com/fangwei123456/spikingjelly.
5. Goodfellow, Ian J., Jonathon Shlens, and Christian Szegedy. 2015. “Explaining and Harnessing Adversarial Examples.” arXiv:1412.6572 [Cs, Stat], March. http://arxiv.org/abs/1412.6572.
6. iThome. n.d. “Day 24 / DL x RL / 決策與 RL.” iT 邦幫忙::一起幫忙解決難題,拯救 IT 人的一天. Accessed February 20, 2022. https://ithelp.ithome.com.tw/articles/10251184.



留言
張貼留言