機器學習 x 聲訊處理 x 適應性濾波器
因為疫情的影響,不論是遠端上班還是線上教育,使用線上軟體進行會議的比例大幅增加,通常都會使用到音響和麥克風來溝通。若是使用頭罩式耳機的話,耳機與麥克風的距離只有約15公分,若會議軟體沒有聲訊濾波器、耳機音量過大、麥克風太敏感...等等的原因,麥克風會再次接受耳機的訊號形成正回饋,不斷的循環下就讓系統癱瘓而產生爆音。因此如何防止聲音回饋的行程相當重要。
Simon Haykin 透過基本的仿生系統,將系統函數(system function)的每個單位當作神經細胞進行學習。模型的細節如下(圖1),X為模型的輸入訊號(公式1),在這個例子中是要送進麥克風發出的訊號。W為每個細胞之間的權重(公式2),當做系統函數的值,初始值為零。y是下游細胞的輸出(公式3),這裡是輸入訊號和系統函數捲積(圖2)。d(n)為麥克風的訊號(公式4)與y相減可以e(n) [error signal]。最後(公式5),W會根據$\eta$[學習常數]、e(n)、輸入訊號大小進行學習。
若學習完成,e(n)會趨近於0,麥克風收到訊號後,會透過學習後的適應性濾波器將可能是同裝置喇叭的聲音濾掉,防止爆音產生。此模型是經典的跨領域結合,利用仿生系統結合訊號處理將雜訊去除。
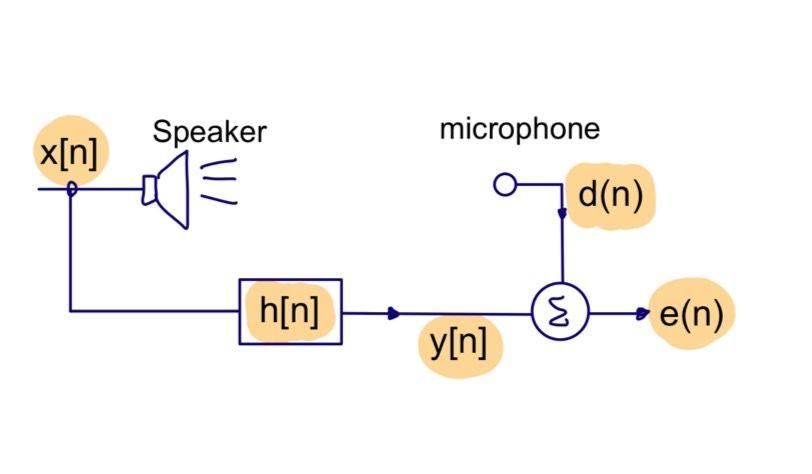 |
| 圖1 模型示意圖,使用情境以及每個符號代表的位置 |
 |
| 圖2 捲積示意圖 (convolution) |
 |
| 圖3 公式列表 |
撰文:謝明儒
參考資料:Kubat, M. (1999). Neural networks: a comprehensive foundation by Simon Haykin, Macmillan, 1994, ISBN 0-02-352781-7. The Knowledge Engineering Review, 13(4), 409-412.



留言
張貼留言